推理模型(Reasoning Models)Beta
OpenAI o1 系列模型是新的大型語言模型,經過強化學習訓練來進行複雜的推理。o1 模型在回答前會先思考,並能在回應使用者前產生長串的內部思考過程。o1 模型在科學推理方面表現出色,在競賽程式設計題目(Codeforces)中排名前 89%,在美國數學奧林匹亞(AIME)資格賽中名列美國前 500 名學生,並在物理、生物和化學問題基準測試(GPQA)中超越了人類博士級的準確度。
API 中提供兩種推理模型
- o1-preview:OpenAI的 o1 模型的早期預覽版,設計用於利用廣泛的世界知識來推理困難問題。
- o1-mini:o1 的更快速且更便宜的版本,特別擅長於不需要廣泛一般知識的程式設計、數學和科學任務。
o1 模型在推理方面提供了重大進展,但並非想要在所有使用場景中取代 GPT-4o。對於需要圖片識別、function calling 或一致快速回應時間的應用場景,GPT-4o 和 GPT-4o mini 依舊是 production環境下最佳的選擇。然而,如果目標是開發需要深度推理且可以接受較長回應時間的應用,o1 模型提供了一個可以進行早期探索的選項。
o1 模型目前處於 Beta 階段
o1 模型目前處於功能有限的 Beta 階段。使用權限僅限於 tier-5 開發者,且有非常低的 Rate limit(20 RPM)。OpenAI 正在努力新增更多功能、提高 Rate limit,並在未來幾週內擴大更多開發者的使用權限,現階段根據模型解決問題所需的推理量,這些請求可能需要從幾秒鐘到幾分鐘不等的時間。
Beta 版限制
在 Beta 階段,大多數 Chat Completion API 的 parameters 都不受支援,最值得注意的如下:
- 僅限文字,不支援圖片解析。
- 僅支援 user role 和 assistant role,不支援 system role。
- 不支援 Stream mode。
- 不支援 function calling。
- 不支援對數概率(Logprobs)。
temperature、top_p和n固定為 1。presence_penalty(存在懲罰)和frequency_penalty(頻率懲罰)固定為 0。- GPT o1 不支援 Assistants API 或 Batch API。
OpenAI 將在未來幾週內逐步退出 Beta 階段時增加對這些參數的支援,多模態和工具使用等功能將包含在 o1 系列的未來模型中。
推理如何運作
o1 模型引入了『推理token』,這些模型使用推理 token 來「思考」,分解它們對提示的理解,並考慮多種產生回應的方式。在產生推理 token 後,模型會以可見的完成 token 產生答案,並從其 context 中去除推理 token。
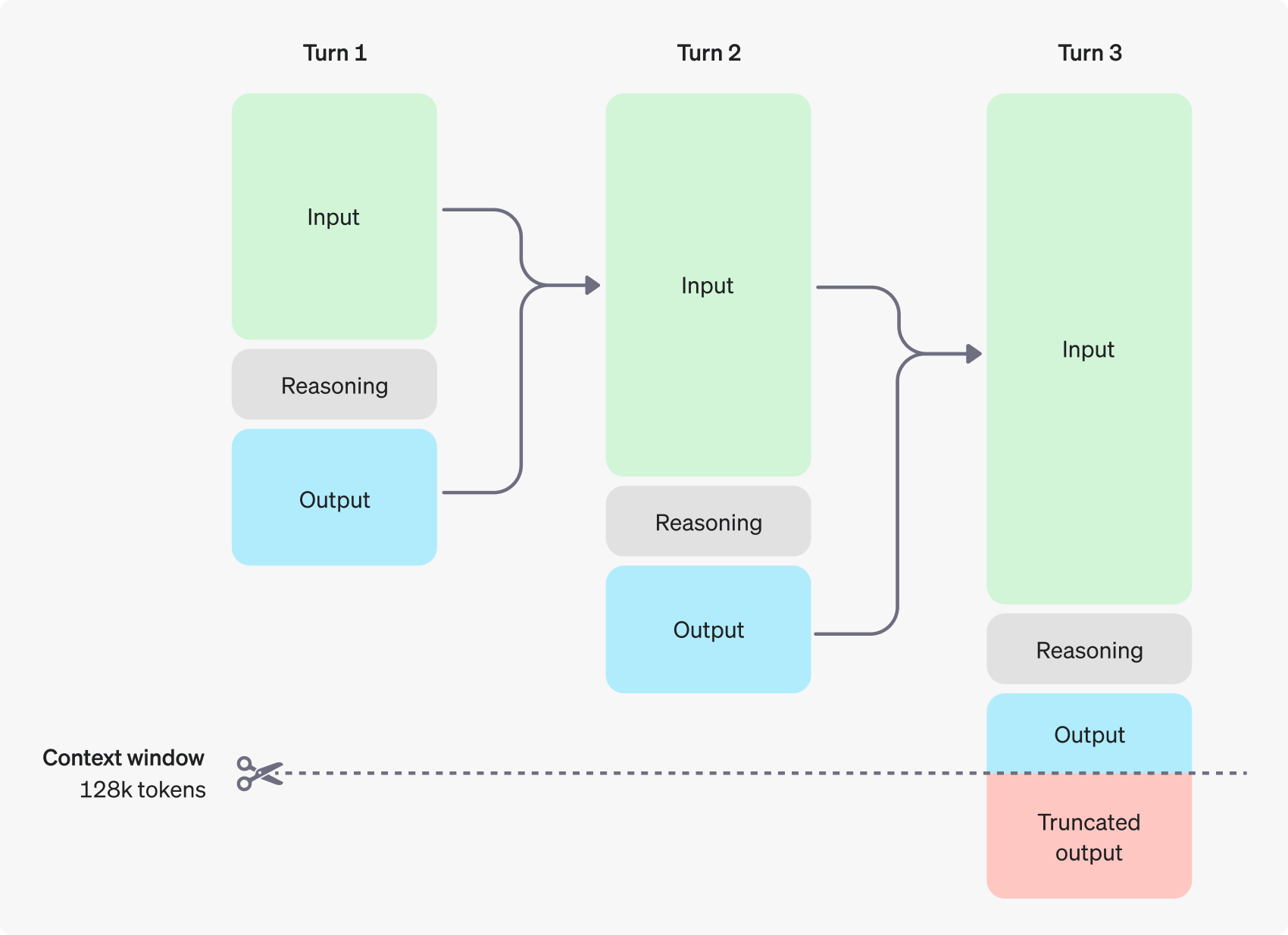
每個步驟的輸入和輸出 token 會被保留,而推理 token 則會被丟棄。OpenAI 官網中圖片展示了三個回合(Turn 1、Turn 2、Turn 3)的推理過程,每個回合都包含輸入(Input)、推理(Reasoning)和輸出(Output)三個階段。每個回合的輸出會成為下一個回合的輸入,形成一個連續的推理鏈。這種方式允許模型在多個步驟中逐步深化和改進其理解和推理。模型能夠處理相當大量的上下文 128k tokens,將較於其他模型,GPT o1 model可以處理和「記住」相對更大量的 context。在第三個回合的底部,有一個標記為「Truncated output」的紅色框。這意思是即使模型有很大的上下文窗口,最終的輸出仍可能需要被截斷,可能是為了適應某些限制或保持輸出的簡潔性。
雖然推論 token 在 API 中不可見,但它們仍然佔用模型 context window的空間,並以輸出 token的方式計費。
管理 Context window
o1-preview 和 o1-mini 模型提供了 128,000 個 token 的 context window。每次完成都有一個最大輸出 token 的上限,這包括了不可見的推理 token 和可見的完成 token。最大輸出 token限制如下:
- o1-preview:最多 32,768 個 token
- o1-mini:最多 65,536 個 token
在產生完成時,確保context window 中有足夠的空間給推理 token 是很重要的。根據問題的複雜程度,模型可能會產生從幾百到數萬個推理 token。使用的推理 token的確切數量可以在 Chat completion 回應的 usage 物件中看到,位於 completion_tokens_details 下:
usage: {
total_tokens: 1000,
prompt_tokens: 400,
completion_tokens: 600,
completion_tokens_details: {
reasoning_tokens: 500
}
}控制成本
為了管理 o1 系列模型的成本,開發者可以使用 max_completion_tokens 參數來限制模型產生的 token 總數(包括推理和完成 token)。在之前的模型中,max_tokens 參數同時控制產生的 token 數和使用者可見的 token 數,這兩者總是相等的。然而,在 o1 系列中,由於內部推理 token 的存在,產生的總 token 數可能會超過可見 token 的數量。因為一些應用程式可能依賴 max_tokens 與從 API 接收的 token 數量相符,o1 系列引入了 max_completion_tokens 來明確控制模型產生的 token 總數,包括推理和可見的完成 token。這種明確的設定確保了在使用新模型時不會破壞現有的應用程式。max_tokens 參數在所有先前的模型中繼續照常運作。
為推理預留空間
如果產生的 token 達到了內容視窗限制或你設定的 max_completion_tokens 值,API 將收到一個 finish_reason 設定為 length 的 chat completion回應。這可能會在產生任何可見的完成 token 之前發生,這表示你可能會因為輸入和推理 token 而產生費用,卻沒有收到可見的回應。為了避免這種情況,記得確保 context window 中有足夠的空間,或將 max_completion_tokens 值調高。OpenAI 建議在開始實驗這些模型時,至少保留 25,000 個 token 用於推理和輸出。隨著你對提示所需的推理 token 數量變得熟悉,你可以相應地調整這個緩衝區。
提示建議
這些模型在面對直接的提示時表現最佳。某些提示工程技巧,如少樣本提示或指示模型「逐步思考」,可能不會提升表現,有時甚至會阻礙表現。以下是一些 Best practices:
- 保持提示簡單直接:這些模型擅長理解並回應簡短、清晰的指示,無需大量指引。
- 避免使用思考鏈提示:由於這些模型內部會進行推理,因此不需要提示它們「逐步思考」或「解釋你的推理過程」。
- 使用分隔符以增加清晰度:使用如三重引號、XML 標籤或段落標題等分隔符,清楚地標示輸入的不同部分,幫助模型適當地解釋不同段落。
- 限制檢索增強生成(Retrieval-Augmented Generation, RAG)中的額外內容:當提供額外的內容或文件時,只包含最相關的資訊,以防止模型過度複雜化其回應。
Prompt samples
OpenAI o1 系列模型可以處理複雜的算法,還能寫出程式。以下這提示要求 o1 根據一些特定標準重構一個 React 元件。
from openai import OpenAI
client = OpenAI()
prompt = """
Instructions:
- Given the React component below, change it so that nonfiction books have red
text.
- Return only the code in your reply
- Do not include any additional formatting, such as markdown code blocks
- For formatting, use four space tabs, and do not allow any lines of code to
exceed 80 columns
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o1-mini",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
],
}
]
)
print(response.choices[0].message.content)這個提示詞是針對一個 React 元件的修改要求,目標是改進現有的書籍列表顯示功能。它要求將非小說類書籍的文字顏色改為紅色,這種修改涉及了條件顯示和樣式處理,實作了前端開發中常見的需求。提示詞特別強調了回覆格式的重要性,要求只返回程式碼,不包含額外的標記或格式化元素,並且明確指定了縮排和行寬的標準。這些嚴格的格式要求反映了開發實務中對程式碼一致性和可讀性的重視。同時,提示詞中包含了原始的 React 元件程式碼,為 AI 提供了明確的起點和上下文。這種方式不僅測試了 AI 對 React 和 JavaScript 的理解,還考驗了它處理具體 coding style 要求的能力。
OpenAI o1 系列模型也很擅長創建多步驟計畫,以下的範例提示要求 o1 為完整解決方案建立檔案系統結構。
from openai import OpenAI
client = OpenAI()
prompt = """
I want to build a Python app that takes user questions and looks them up in a
database where they are mapped to answers. If there ia close match, it retrieves
the matched answer. If there isn't, it asks the user to provide an answer and
stores the question/answer pair in the database. Make a plan for the directory
structure you'll need, then return each file in full. Only supply your reasoning
at the beginning and end, not throughout the code.
"""
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
},
],
}
]
)
print(response.choices[0].message.content)以下是提示詞的解析:
I want to build a Python app that takes user questions and looks them up in a database where they are mapped to answers. If there ia close match, it retrieves the matched answer. If there isn't, it asks the user to provide an answer and stores the question/answer pair in the database. Make a plan for the directory structure you'll need, then return each file in full. Only supply your reasoning at the beginning and end, not throughout the code.這個提示詞描述了一個具有特定功能的 Python 應用程式開發需求,並要求 AI 提供詳細的設計和實現方案。該應用程式的核心功能是處理使用者問題,在資料庫中查找適合的答案,如果找不到則要求使用者提供答案並儲存。這個需求涉及了資料庫操作、使用者互動和文字比對等多個方面,嘗試實作一個典型的問答系統的基本架構。提示詞特別強調了要提供完整的目錄結構計劃和每個檔案的完整內容,這要求 AI 不僅要考慮功能實現,還要思考整個專案的組織結構。同時,提示詞明確指出只在開始和結束時提供推理說明,這種要求旨在獲得一個清晰、直接的程式碼輸出,便於開發者快速理解和實作。這個提示詞展示了如何利用 AI 來輔助軟體開發過程,從專案規劃到具體實現,為開發者提供一個全面的起點。
OpenAI o1 系列模型在 STEM 研究方面表現出色,在一些基礎研究的問題上的生成品質相當不錯。
from openai import OpenAI
client = OpenAI()
prompt = """
What are three compounds we should consider investigating to advance research
into new antibiotics? Explain your reasoning.
"""
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": prompt
}
]
)
print(response.choices[0].message.content)這個提示是一個深入探討抗生素研究領域的專業問題,要求 AI 模型提出三種值得研究的化合物,並解釋選擇這些化合物的理由。這個問題不僅測試了 AI 在化學、微生物學和藥理學等領域的知識廣度,還考驗了它的分析能力和創新思維。通過要求解釋選擇背後的邏輯,這個提示鼓勵 AI 深入思考並提供有見地的回答。這種方法可能對研究人員、學生或跨領域專家特別有價值,因為它可以激發新的研究方向,或者驗證現有的研究思路。不過 AI 的回答應該被視為起點或參考,而非確定的科學結論。
目前我最喜歡 OpenAI o1 model 的地方是可以透過研究 OpenAI o1 model的 reasoning過程來強化許多 Agentic 任務的 workflow設計…
然後需要注意的是 OpenAI o1 model是目前『最貴』的模型
o1-preview $15.00 / 1M input tokens 每百萬輸入 token是 gpt-4o-2024-08-06 的 6倍
o1-preview $60.00 / 1M output tokens 每百萬輸出 token 是 gpt-4o-2024-08-06 的 6倍
-1024x576.jpg)